SelectDB
什么是SelectDB
SelectDB是基于Apache Doris 研发的,基于 MPP 架构的高性能、实时的分析型数据库。
应用场景
-
在线高并发报表与分析 使用云数据库 SelectDB 版处理在线高并发报表,获得实时、快速、稳定、高可用的服务,支持数据实时写入、亚秒级查询响应、高并发点查询,满足集群高可用部署需求。
-
用户画像与行为分析 基于建设用户CDP数仓平台(数据管理平台),支持毫秒级加列以及动态表灵活应对业务变动,支持丰富的行为分析函数带来开发简化和效率提升,支持高表正交位图实现画像场景的秒级圈人。
-
湖仓一体的现代化数据平台 统一数据仓库和数据湖到单一平台,提供高性能的商业智能报表、Adhoc分析,以及增量ETL/ELT数据处理的能力。
-
日志存储与分析 将日志系统接入到云数据库 SelectDB 版,实现日志的实时查询、低成本存储、高效处理,降低企业日志系统综合成本,提升日志系统的性能和可靠性。
基本结构
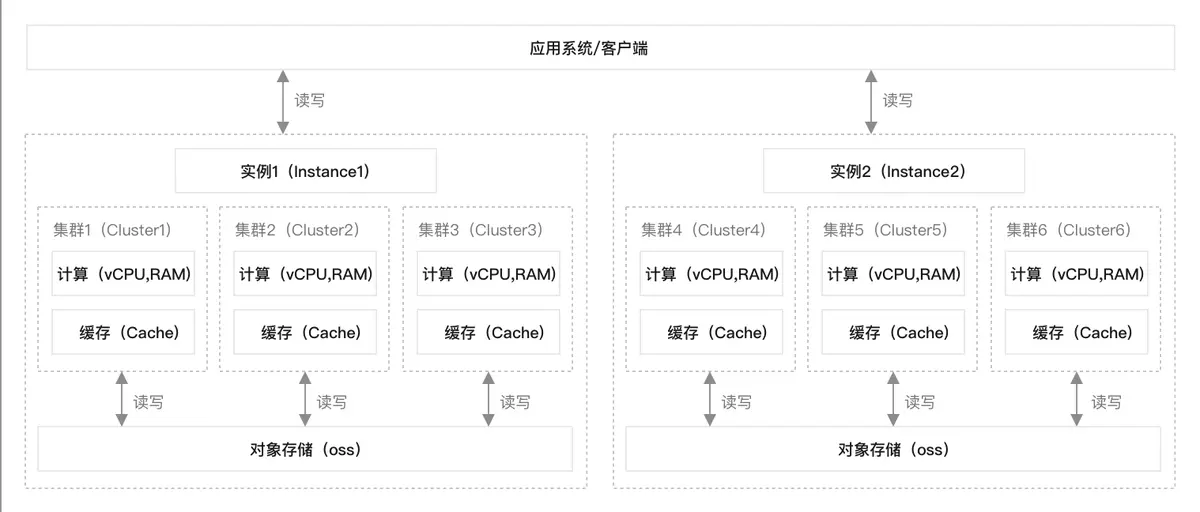
使用接口
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。兼容 MySQL 生态的命令行工具、JDBC/ODBC 和各种可视化工具。
数据模型
数据以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column)。Row 即用户的一行数据,Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。Doris 的 Key 列是建表语句中指定的列,建表语句中的关键字 unique key 或 aggregate key 或 duplicate key 后面的列就是 Key 列,除了 Key 列剩下的就是 Value 列。
Doris 的数据模型分为 3 类:
明细模型(Duplicate Key Model)
在明细数据模型中,存储层会保留写入的所有数据。即使两行数据完全相同,也都会保留。建表语句中指定的 Duplicate Key,只是用来指明数据存储按照哪些列进行排序,可以用于优化常用查询

主键模型(Unique Key Model)
主键模型能够保证 Key(主键)的唯一性,当用户更新一条数据时,新写入的数据会覆盖具有相同 key(主键)的旧数据。

聚合模型(Aggregate Key Model)
根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。

目前有以下聚合方式:

分区与分桶
数据以关系表(Table)的形式进行呈现,会依次按照先分区(Partition)、再分桶(Bucket)的方式划分,最终在同一个分桶中的数据会形成数据分片(Tablet)。Tablet 是 Apache Doris 中多副本高可用、集群间数据调度与均衡的最小物理存储单位。
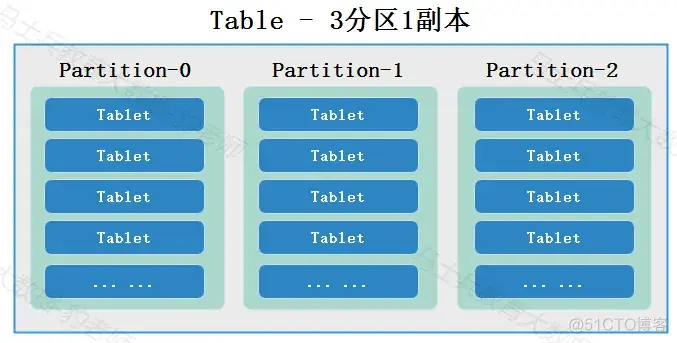
分区是物理上的隔离,分桶是逻辑上的隔离
分区
List Partition
List Partition 相当于对分区的列值进行枚举,因此选择的分区列最好是有区分度的可枚举值,例如本例中的 city。根据 city 列的枚举值创建多个 List Partition,则 PARTITION_DESC可以写为:
-- 以city作为分区列,创建华北、东北、华中、西南等分区
PARTITION BY LIST(city)
(
PARTITION `p_huabei` VALUES IN ("beijing", "tianjin", "shijiazhuang"),
PARTITION `p_dongbei` VALUES IN ("shenyang", "dalian"),
PARTITION `p_huazhong` VALUES IN ("wuhan", "changsha")
PARTITION `p_xinan` VALUES IN ("chengdu", "chongqing")
)
Range Partition
创建 Range partition 一般使用时间列,Range Partition 又可以分为静态和动态两种方式:
- 静态 Range Partition
此类 Partition 的创建会生成一个左闭右开的区间,定义一个分区只需要指定右边界,该分区的左边界由上一个分区的右边界确定,PARTITION_DESC可以写为:
-- 以sdate这个时间列作为分区列,
-- 日期处于[min, 2023-01-01)的数据,都放到名为p2022的分区下;
-- 日期处于[2023-01-01, 2023-01-02)的数据,都放到名为p20230101的分区下;
-- 日期处于[2023-01-02, 9999-12-31)的数据,都放到名为pmax的分区下;
PARTITION BY RANGE(sdate)
(
PARTITION `p2022` VALUES LESS THAN ("2023-01-01"),
PARTITION `p20230101` VALUES LESS THAN ("2023-01-02"),
PARTITION `pmax` VALUES LESS THAN ("9999-12-31")
)
可以看出,p20230101 这个分区的左边界由 p2022 分区的右边界确定,而 pmax 的左边界由 p20230101 的右边界确定。需注意的是,此处为了举例说明动态分区,使用了一个很大的边"9999-12-31",实际业务中很少会直接创建从 2023-01-02 到 9999-12-31 的分区。
动态 Range Partition
上述静态的分区需要手动指定边界,分区个数太多使用起来也不方便。动态 Range Partition 帮助我们解决了这个问题,只需指定一些分区的参数即可动态创建,PARTITION_DESC 相对更简单,只需指定哪个列作为分区列即可:
PARTITION BY RANGE(sdate)()
剩余参数需要在PARTITION进行配置:
PROPERTIES (
"dynamic_partition.enable" = "true", -- 动态开启
"dynamic_partition.time_unit" = "DAY", -- 分区单位,yer,month,week等
"dynamic_partition.start" = "-30", --以当前时间为准,保留多少个单位时间内的分区数,超出的自动删除
"dynamic_partition.end" = "3", --未来得空分区数
"dynamic_partition.prefix" = "p", -- 分区名前缀
"replication_num" = "1" -- 副本数
);
分桶
分桶在物理层面即数据分片(Tablet)。在数据表完成分区后,指定部分列作为分桶列,将这些列数据中相同哈希值的数据合到一起,形成了 Tablet。一个表中 Tablet 总数量 = 分区数(Partition num)x 分桶数(Bucket num)x 数据副本数(Replication_num) 。
[BUCKET_DESC] 语句非常简单,只需要一句:
DISTRIBUTED BY HASH(site) BUCKETS 20
关于 Partition 和 Bucket 的数量和数据量的建议
1.一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
2.一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
3.单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,
则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,
且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
4.当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
5.一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。
比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,
也不能提高并发度。
前缀索引
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。 即只能在在Key的Column上有索引,Value的不能;且需要按照Key的顺序查询,将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断
BloomFilter索引
布隆过滤器索引,Bloom Filter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内。而如果返回true,则有可能在这个集合内。
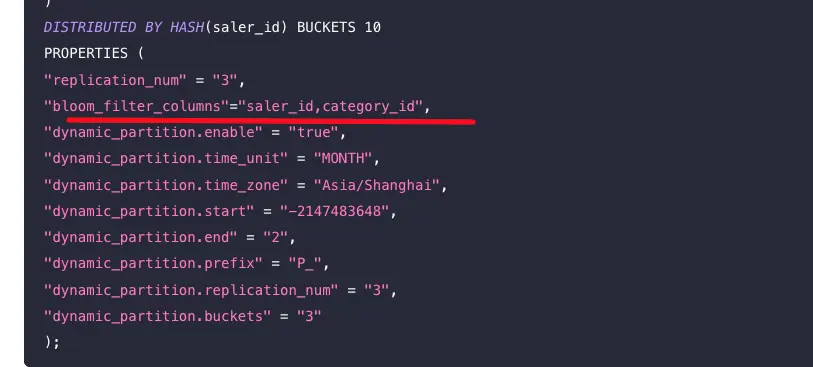
- 首先BloomFilter适用于非前缀过滤。
- 存储这个额外的索引层次会占用额外的空间
- 不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
- BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。
- Bloom Filter索引只对 in 和 = 过滤查询有加速效果。
Bitmap 索引
与数据库Bitmap索引创建、使用类似。